
Разработчики лаборатории нейронных систем и глубокого обучения Исследовательского центра прикладных систем ИИ МФТИ предложили новый полуавтоматизированный алгоритм разметки данных для искусственного интеллекта. «Репетиторами» для языковой модели стали краудсорсеры (разметчики на рилансе), а также ChatGPT. Теперь на подготовку данных для обучения нейросети нужно в 3 раза меньше времени и в 2 раза меньше денег. Проект представлен в международном научном журнале ACL Anthology.
Зачастую чат-боты ошибаются из-за того, что не могут точно определить, чего хочет пользователь. Как правило, это связано с тем, что выразить мысли словами пользователь чат-бота может по-разному, а диалоговая система на основе языковой модели внутри чат-бота не знает, как на какие-то из запросов реагировать. Причиной может быть недостаточное количество примеров, на которых обучалась языковая модель, и/или недостаточное качество этих примеров.
В основе любой системы искусственного интеллекта, как правило, лежат закономерности, «выученные» моделью из обучающих данных — большого количества примеров, — подобно тому, как обнаруживает и обобщает различные закономерности человек. Если примеров слишком мало, модель не сможет на них чему-нибудь «научиться» — как человек не освоит арифметику, если дать ему лишь пару примеров вроде «2+2=4» и «5×5=25». Если данные для обучения некачественные, то модель также может просто не найти какие-нибудь правильные закономерности, либо найти неверные закономерности — например, как если бы человек учился арифметике на примерах, среди которых было бы множество некорректных, вроде «3+3=33» и «5+5=55».
Для подготовки и разметки данных для обучения в виде, пригодном для обучения моделей искусственного интеллекта, необходимы специалисты – аннотаторы. Они выполняют роль репетитора: тщательно готовят и разбирают примеры, которые позволяют обучать модели. Этот процесс называется разметкой или аннотацией данных.
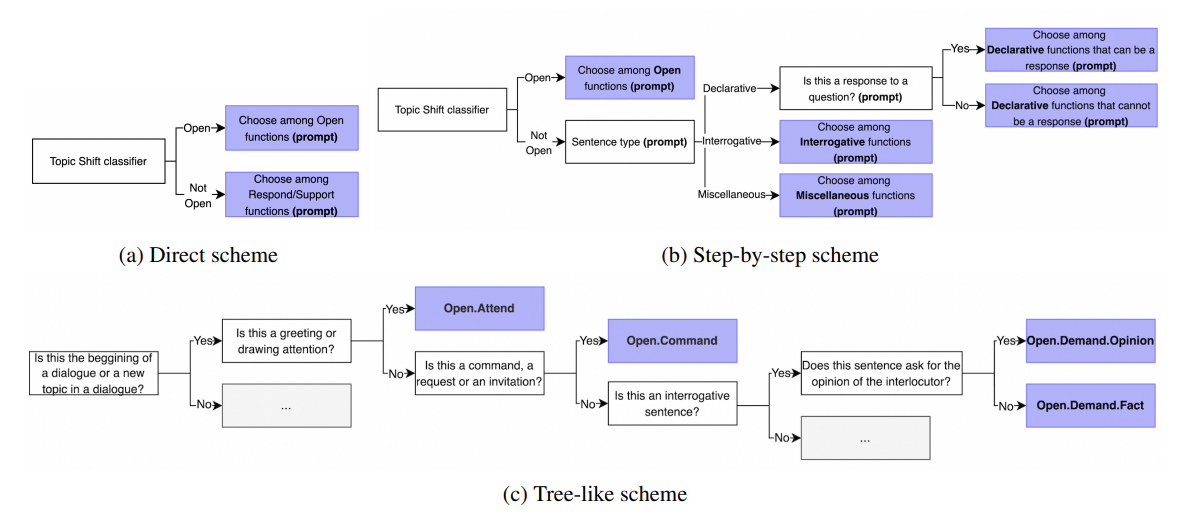
Для одной из прикладных задач, с которой столкнулись специалисты МФТИ, требовалось разработать модель, позволяющую более качественно определять запросы и пожелания пользователей. Чтобы создать «умного ассистента» с точки зрения лингвистики, нужно научиться не только определять значения отдельных слов, но и проводить анализ структуры фраз и внутренней логики языка, понимать контекст в диалоговых данных.
Аннотация данных, особенно применительно к сложным типам разметки (например, таким как разметка реплик в диалоговых данных в соответствии с теорией речевых функций), да ещё с условием, чтобы соблюдалось постоянство разметки, — трудоёмкая задача, требующая длительной монотонной и внимательной работы аннотаторов.
Как следствие, разметка данных — долгий (порой доходящий до нескольких месяцев) и дорогой процесс. Даже компания OpenAI, создатель ChatGPT, столкнулась с необходимостью снизить расходы путём аутсорсинга разметки данных компании Sama — по материалам, полученным TIME, в конце 2021 года OpenAI заключила с Sama три контракта на аннотацию данных на общую сумму около двухсот тысяч долларов США, а работы выполнялись сотрудниками кенийского подразделения Sama в течение нескольких месяцев.
Чтобы снизить стоимость разметки, можно вместо профессиональных лингвистов привлекать краудсорсеров (разметчиков на фрилансе). Однако в процессе краудсорсинга качество разметки не просто проконтролировать, особенно на сложных в разметке данных. Во-первых, краудсорсеры могут выбирать ответы случайным образом, что необходимо дополнительно отслеживать. Во-вторых, даже если несколько разметчиков приходят к одному и тому же мнению, это не гарантирует высокого качества данной аннотации. Для того, чтобы оценить качество выполненной работы, необходимо также привлекать обученных разметчиков или экспертов в рассматриваемой области. Таким образом, хотя это и дешевле, чем разметка лингвистами, краудсорсинг — сложный процесс, требующий контроля и использования дополнительных инструментов для постоянного оценивания работы разметчиков.
Ученые исследовательского центра прикладных систем искусственного интеллекта МФТИ предложили оригинальный способ решения проблемы длительности и высокой стоимости разметки — создали полуавтоматизированную систему для разметки диалоговых данных. Для этого они попробовали сымитировать человеческую разметку лингвистических данных для обучения специализированных моделей с помощью другой нейросетевой модели, ChatGPT.
Для составления данной системы были привлечены опытные эксперты-лингвисты, которые разработали схемы аннотаций. Эти инструкции улучшили качество обработки сообщений. Поскольку большинство лингвистических теорий описывают довольно субъективные категории (зависящие от интерпретации одного человека), простые методы работы с большими языковыми моделями не дают желаемых результатов для решения задачи. По этой причине требуются более креативные подходы к аннотации таких данных: более подробные инструкции для модели, включающие иллюстративные примеры, дробление задачи на более мелкие подзадачи.
Мы сравнили разметку дискурса в диалогах экспертов, краудсорсеров и больших языковых моделей. Пришли к выводу, что c помощью большой языковой модели можно добиться качества обработки информации, сравнимого с краудсорсерами. Это потребовало разработки многоступенчатой иерархической схемы для разметки. В таком случае эксперты требуются только для предварительной разметки и разработки этой иерархической схемы разметки. Преимущества данного подхода: намного быстрее и дешевле, чем краудсорсинг. Более того, модель размечает данные более консистентно (обеспечивая последовательность, постоянство разметки подобных данных), чем краудсорсеры и даже эксперты, то есть вероятность, что подобные или даже одинаковые реплики в одинаковом контексте будут размечены одинаково у нашей системы выше, чем в случае разметки людей», - прокомментировала Мария Молчанова, исследователь и аналитик лаборатории нейронных систем и глубокого обучения МФТИ.
Разработанный алгоритм разметки может иметь широкое применение для аннотации лингвистических данных. Описанный подход был успешно апробирован для разметки диалоговых данных, на которых далее обучались модели управления диалогом с пользователем диалоговой системы в рамках научных исследований лаборатории. Аналогичный подход к разметке диалогов хорошо зарекомендовал себя и в работе над одним из научно-исследовательских проектов с ПАО Сбербанк, являющимся индустриальным партнером ИЦ прикладных систем ИИ МФТИ.
Эксперты тратят в среднем 14,5 минут на аннотацию одного диалога, в то время как краудсорсеры затрачивают 29 минут на ту же работу. Время, необходимое для выполнения задачи с помощью ChatGPT, всегда разное, тем не менее, в среднем, небольшой диалог может быть аннотирован за 10 минут. Что же касается стоимости, то аннотирование с помощью ChatGPT варьируется в зависимости от длины древовидной структуры конкретного диалога от 0,03$ до 0,07$, в то время как работникам краудсорсинга необходимо платить от 0,12$ до 0,22$ за аннотацию одного диалога», - уточняет исследователь Лаборатории нейронных систем и глубокого обучения Лидия Остякова.
Теперь создавать языковые модели стало проще — разработанная в стенах МФТИ методология позволит в разы сократить и время, и стоимость аннотации данных, которые необходимы для дальнейшего обучения языковых моделей, с помощью системы, облегчающей процесс разметки. Автоматизация труда аннотаторов позволяет готовить достаточное количество качественных обучающих данных для дальнейшего прикладного применения.